This is a syndication of my post on the ComplyAdvantage Technology Blog (Check it out and give my colleagues some love!). At the time of writing, I am working at ComplyAdvantage as a Principal Software Engineer.
This is an annotated version of a session presented at the virtual track of the Distributed SQL Summit 2024, Tuesday 12th November 2024. It covers some (of the many) lessons we learned while building a new platform over the last 18 months using the Distributed SQL database (YugabyteDB).
You can watch the session, or if you prefer read through the annotated slides in this post which contain a transcript of the session.


Hi, I’m Mark - a Principal Software Engineer at ComplyAdvantage. At ComplyAdvantage, we build a SaaS risk intelligence platform to help compliance teams tackle financial crime.
At the beginning of 2022, we embarked on a journey to unify our independent product offerings into a single platform to provide a unified user experience for our clients.
I’m here because we chose a Distributed SQL database - YugabyteDB - to form the core of our transactional data storage layer. I’m going to talk through a couple of things we learned over the course of the last 18 months.

But before we get to the lessons, I want to briefly talk about why we chose YugabyteDB and what our estate looks like at the moment.
We had previously selected YugabyteDB to power one of our services that needed a Cassandra-style key-value-based store, and wanted to standardise it on a single database for our relational data storage needs. That didn’t necessarily need to be the same database that we were using for key/value stores. After testing various options, YugabyteDB met our performance, scalability, and budget requirements, and it made sense to extend our existing use of YugabyteDB for our relational needs.
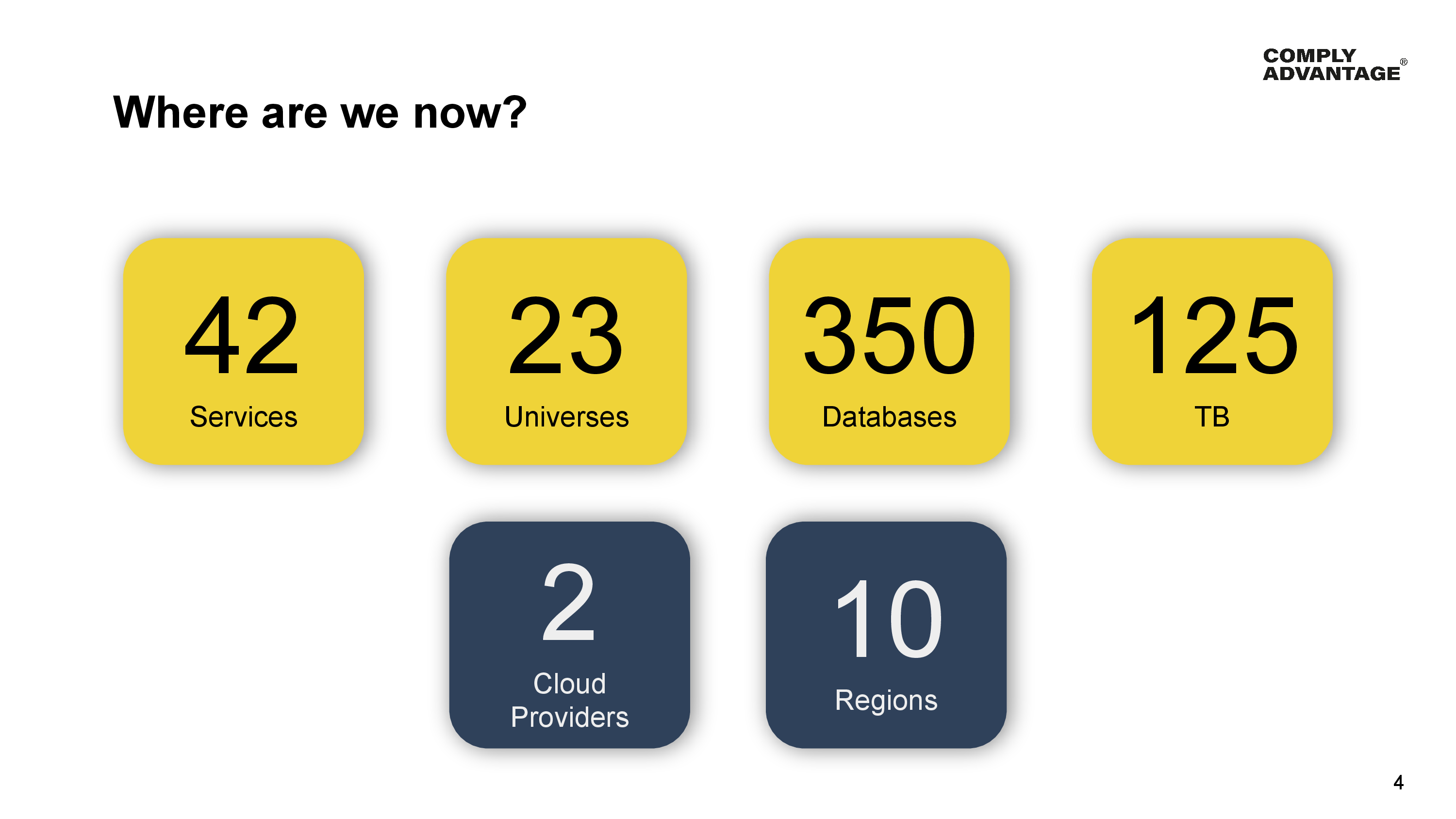
Over the last 18 months, we’ve built or moved 45 new and existing services over to YugabyteDB. These are served by 23 separate universes with a total of 350 databases and 125 terabytes of data under management.
Our estate is spread over 2 cloud providers - Google Cloud and AWS - and 10 geographic regions, and we’re just really getting started.
Over the next year, we’ll be migrating existing clients from our current products to our new platform, leading to an explosion in the volume of data being processed by these universes.

And now onto the lessons. I’m here to talk about a couple of lessons we learned - and there are a lot - but today I wanted to share two of them with you.
These two tripped us up a few times, so I thought were the most important to highlight today. The first lesson is about understanding data distribution and the second is about how you sometimes need to tailor your SQL for running on a Distributed SQL database.

So let’s dive straight into our first lesson - how data distribution across your cluster can impact your schema design.
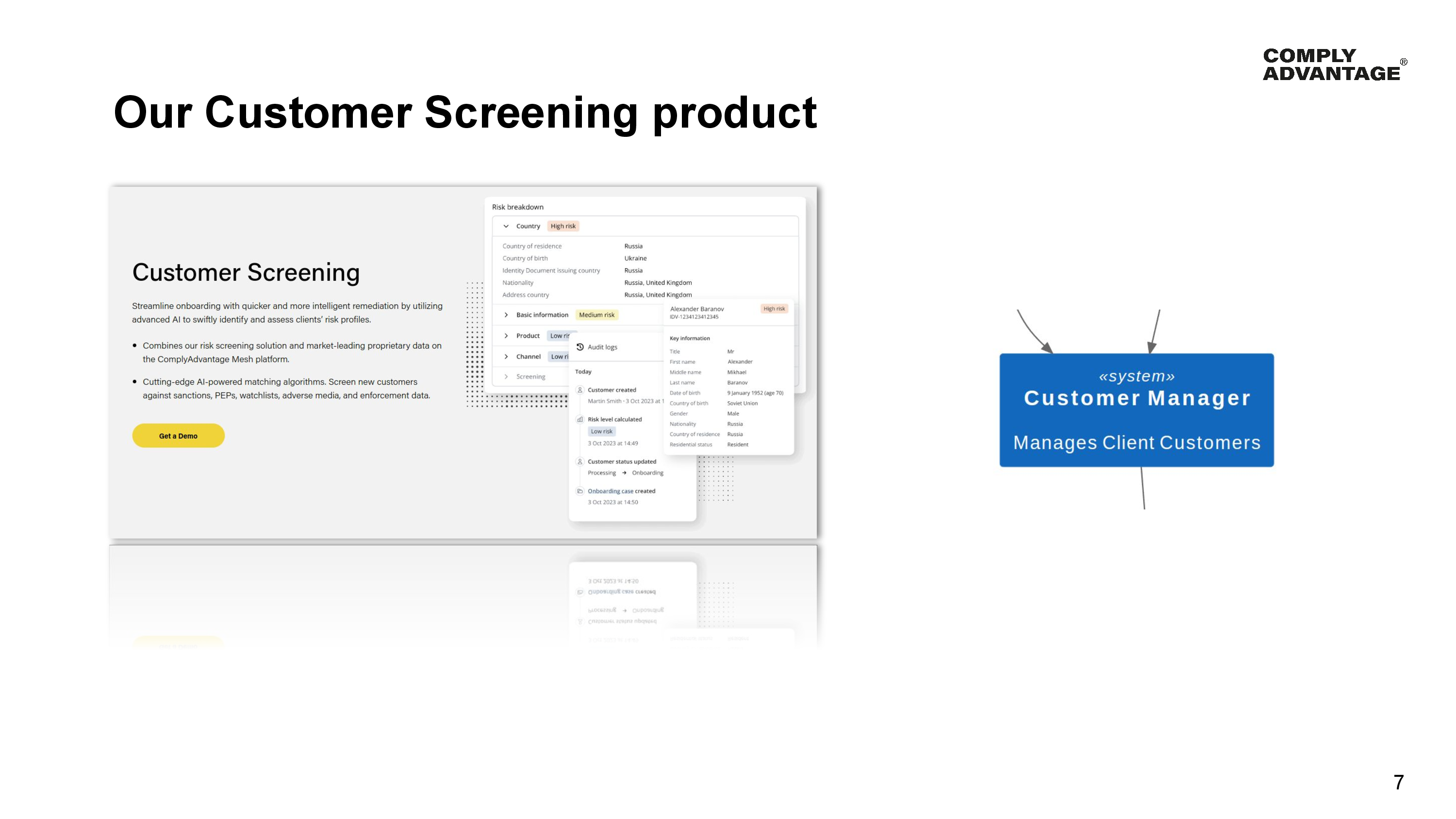
One of our products within our AML platform is our Customer Screening product. When our clients send us their customer data, we perform risk analysis on those customers. We do things like Risk Scoring and Screening for Sanctions amongst others.
If you look at our C4 System Context diagram, one of the services in the platform is the Customer Manager. The Customer Manager is the source of truth within our platform for each and every Customer that our Clients send us.

With a new platform comes a clean slate, and we needed to come up with a Customer table schema. Now obviously our real customer schema has a few more fields than this, but this is enough to demonstrate our first data distribution lesson.
We start off with a basic schema for our Customer record. The table schema consists of the client account identifier, customer identifier, and the full name of the customer. But of course, we need a primary key for this data, so we add a primary key using the account and customer identifiers to ensure we can load the Customers within an Account by their identity.
We move our first ticket to a completed state and ship our Customer Manager.
And all is well for a while, but…

A few months later, our infrastructure team raised a ticket. The database is not happy. One node in the cluster is doing a lot more work than the others.
They attach a helpful chart from our observability system showing the imbalance. This node is doing more than any other by a significant margin, and they have managed to narrow down the problem to our Customer Manager’s schema.
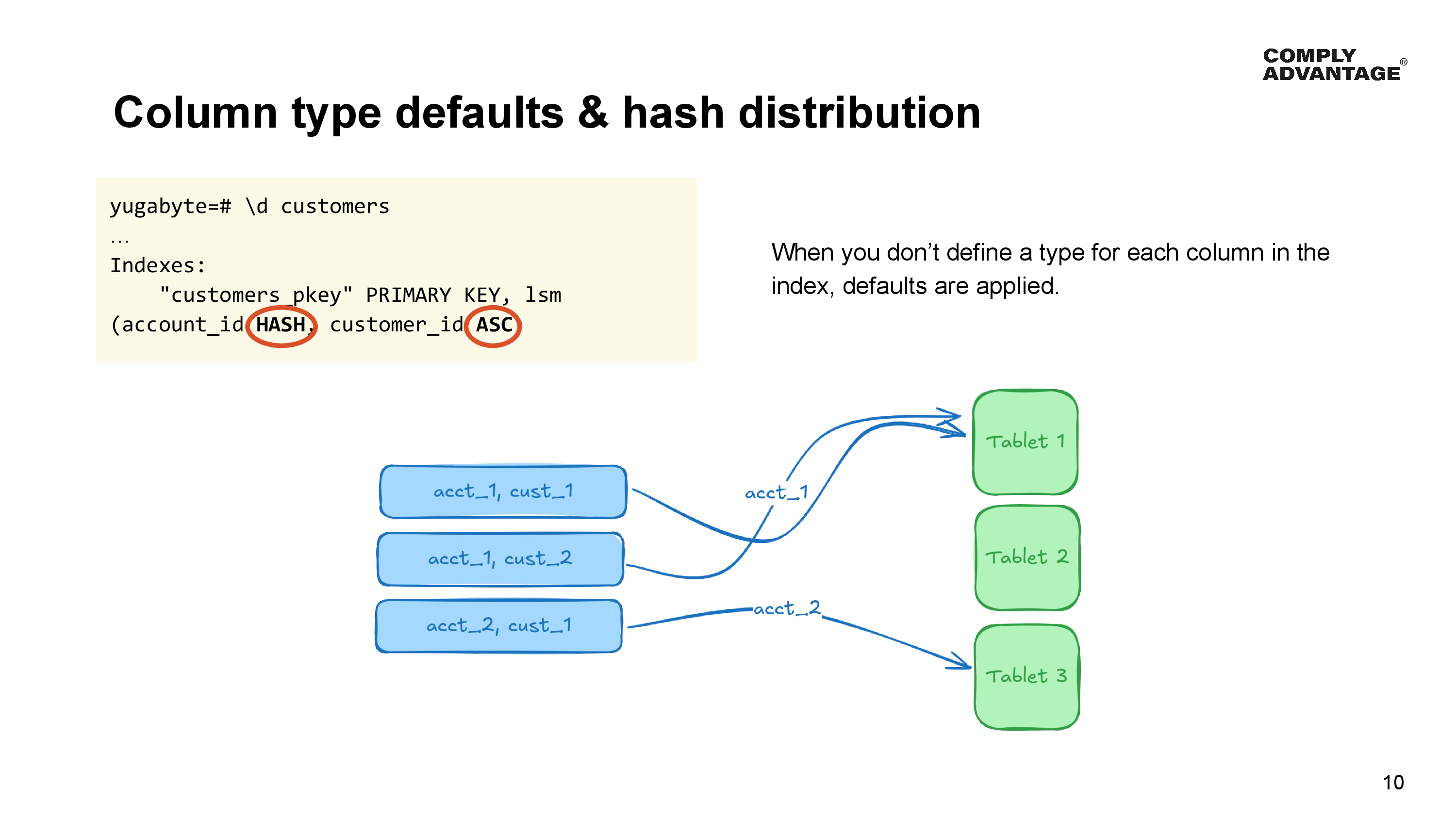
So what has happened? Well, when you do not specify the column type in a primary key, YugabyteDB applies some defaults.
The first column becomes the hash. The hash column is used to route data into specific tablets. The remaining columns in the index are sort columns defaulted to ascending sort order.
Because rows in a table are distributed into tablets using the Hash component of the primary key. In our Customer Manager example, this means that all the rows for each account are stored in the same tablet and within each tablet, the rows are sorted by the customer_identifier column.
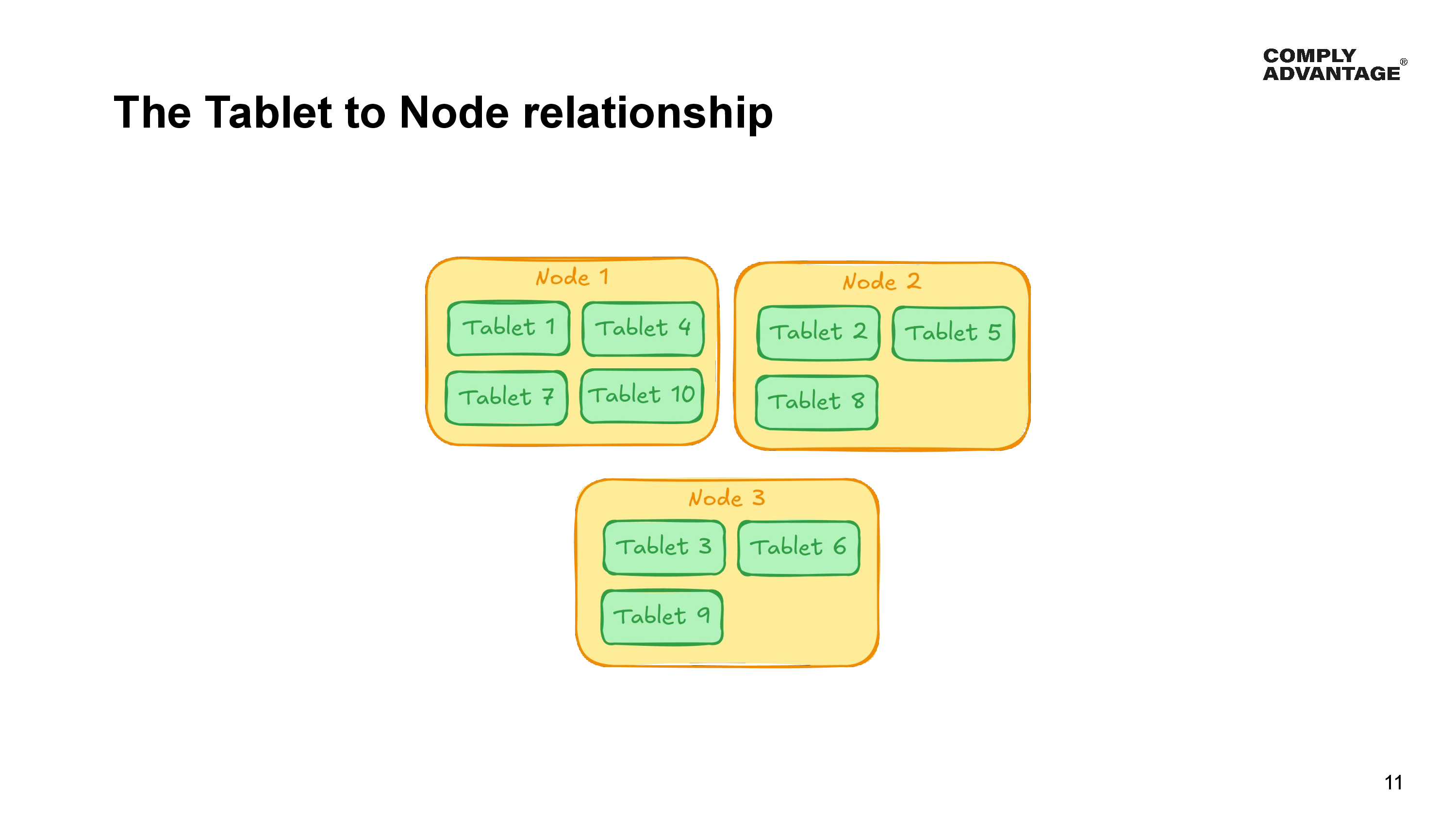
Now a tablet is the smallest unit of “storage” provided by YugabyteDB and is the method that Yugabyte uses to distribute data across the cluster. Each table can be split into multiple tablets, and each tablet is stored on a single node in the cluster and replicated to other nodes based on your replication factor configuration. A single node can store many tablets. It can even store multiple tablets belonging to a single table. When a statement executes, it may need to modify data in, or query data from more than one tablet on more than one node in the cluster.

The problem is that not all of our client accounts are the same. We serve small legal offices with thousands of customers, and we serve large financial institutions with tens to hundreds of millions of customers. This, combined with our schema definition, causes an imbalance in the cluster with some tablets storing significantly more data than others.
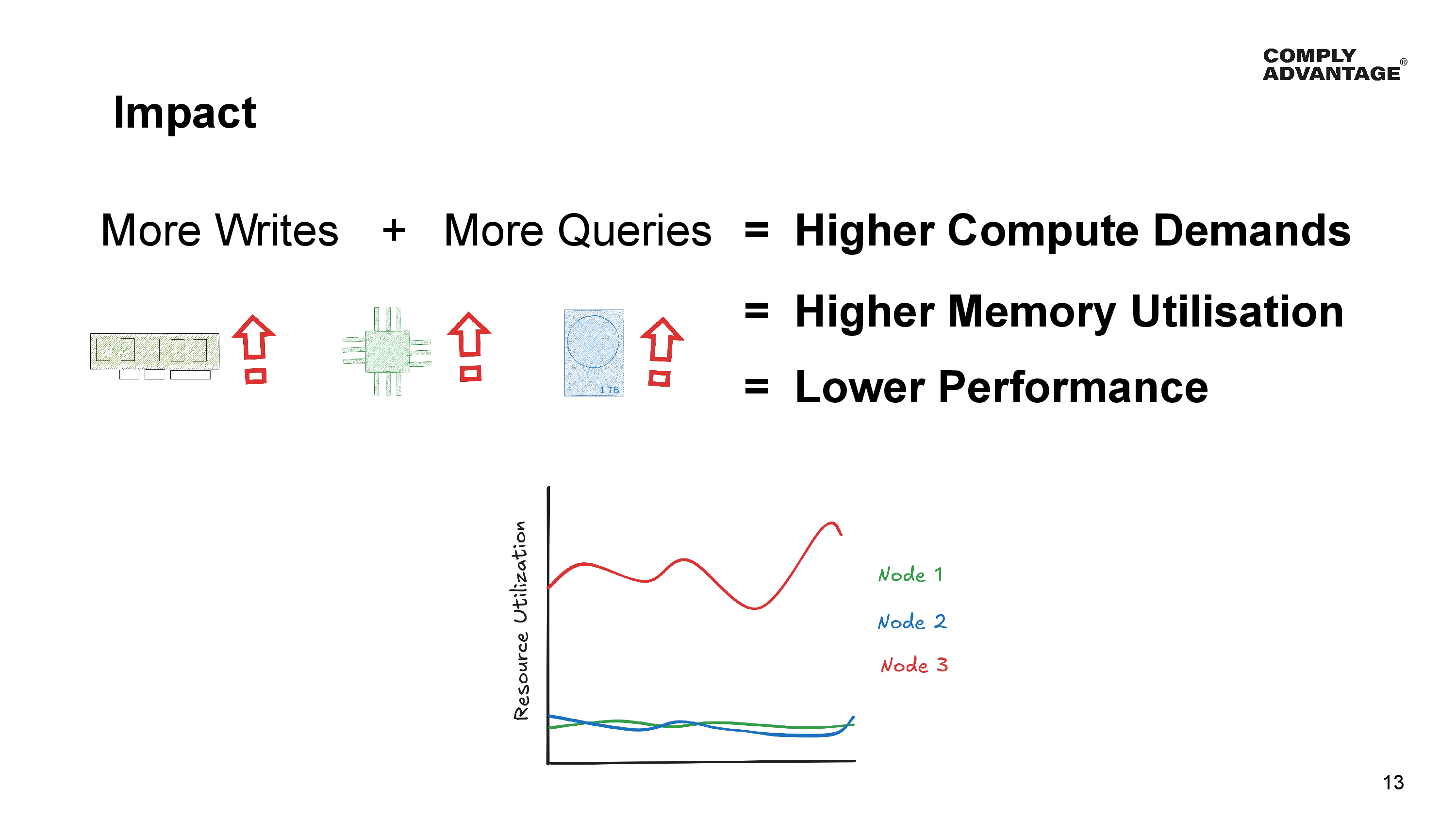
When so many records are disproportionately going to a single node in the cluster, that node has to naturally handle significantly more writes. Not only that, it also has to satisfy a larger proportion of the queries and since a single node in the cluster has to handle so much more work, that node needs more computing than other nodes and requires more memory, not to mention larger disk sizes overall.
This ultimately leads to lower performance than if the data was more evenly distributed across the cluster and given all nodes in a cluster are homogenous in their hardware configuration, the nodes need to be scaled vertically both in compute, memory and disk to satisfy the demands of the largest Account in our Customer Manager.
This results in underutilized nodes and higher overall operational costs than would be required if the data were more evenly distributed.
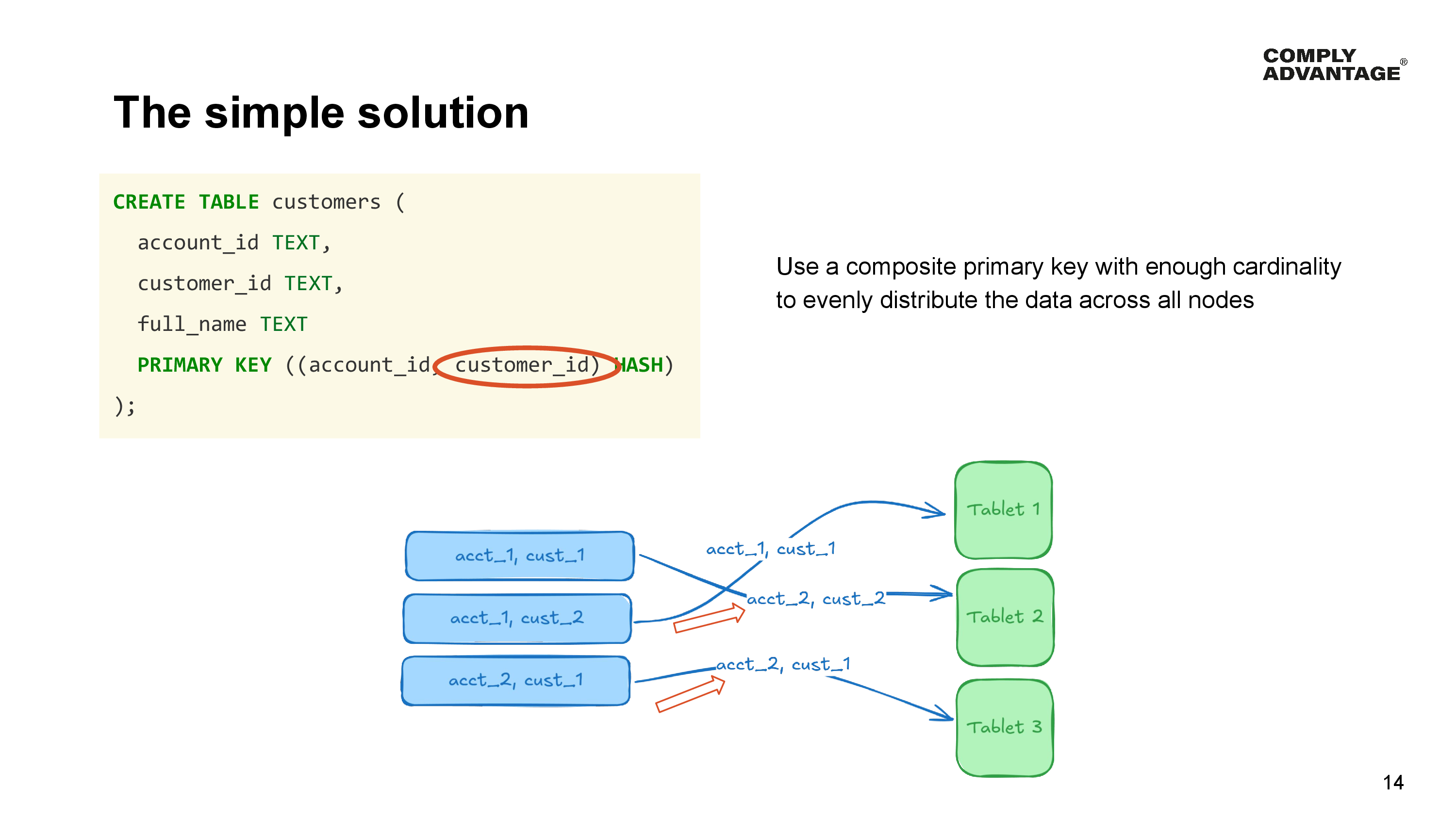
Thankfully there’s a simple solution to this problem - using a composite primary key with enough cardinality to evenly distribute the data across the entire cluster.
For those that have not thought much about the cardinality of their data before - which is a lot of engineers with a background in traditional SQL. What I mean is simply how many unique data points there are in the table for a particular column.
In our example, the account identifier is low cardinality - we might have only a few thousand unique account identifiers, but a customer identifier is high cardinality in this table since every single customer has a unique identifier. So by adding the customer identifier to the hash part of our primary key, we give YugabyteDB’s hashing mechanism the power to evenly distribute the rows across all the tablets. Even within a single account, the customers will be spread across multiple tablets as shown here for the customers in our second account. Previously they had to be grouped into the same tablet, but now can be split across all tablets.

OK we’ve solved that problem and things are back to normal, but a new requirement arrives from Product - a request to allow the users to limit the list of customers to those in a certain state.
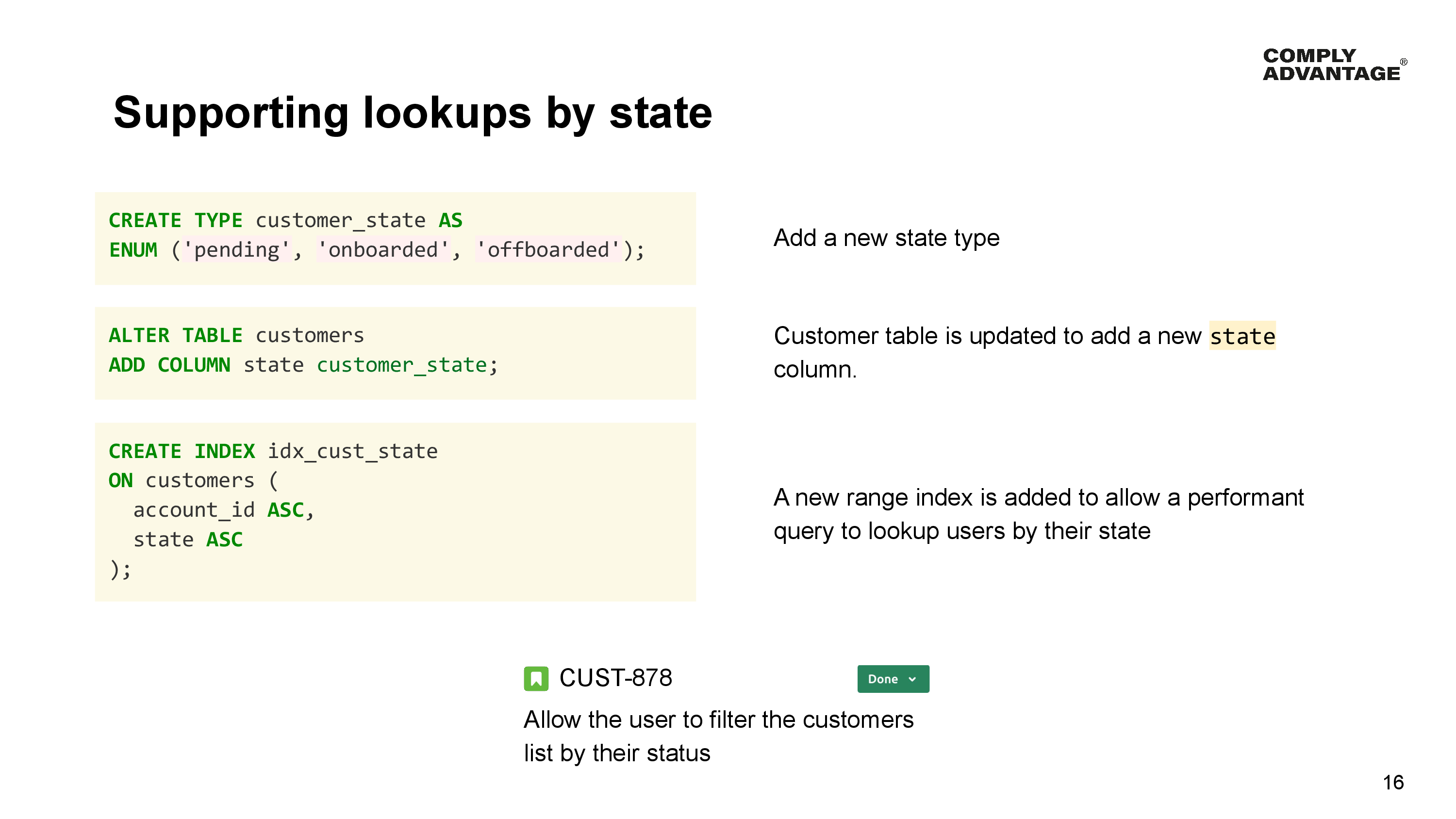
A new enumeration type is added to record the list of valid states. The table schema is updated to add the new column to record the Customer’s state, and we add a new range index to satisfy the database query needed to select customers by state.
Range indexes allow you to store sorted data, and have that data be distributed across the cluster.
We’re done, and we ship it.

But you guessed it - a day later we got a ticket filed by our infrastructure team. They are seeing the same problem as before.
So how does a range index work?
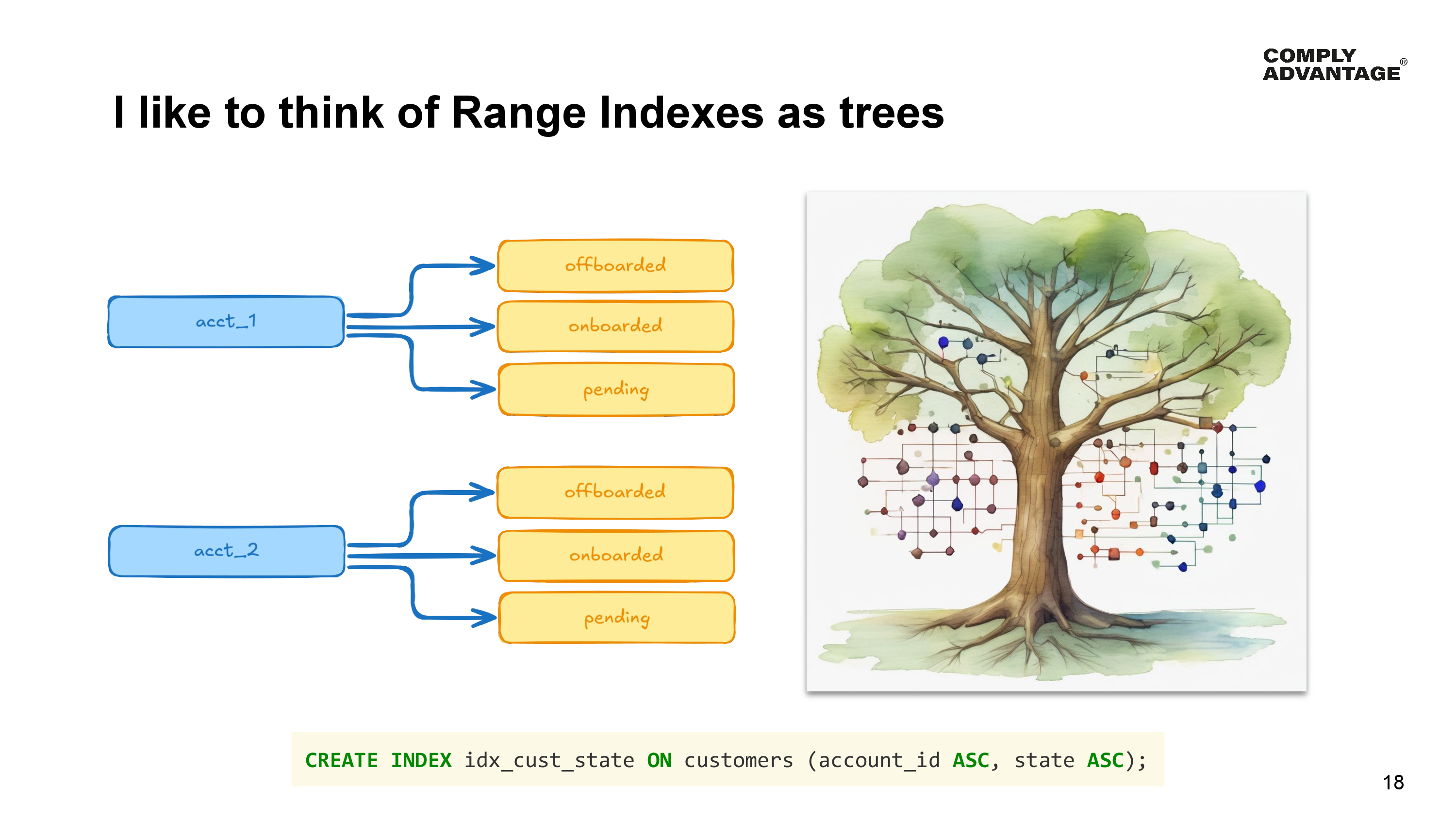
For the purposes of data distribution within the index, I like to think of a range of indexes as trees in a forest. Each tree starts with the value of the first column in the index. This is the trunk. In our example, this is the account identifier column, so each account has its own tree. The next column in the index branches off the trunk, in our example that’s a new branch off the trunk for each state - one for offboarded, onboarding and pending, with any subsequent columns in the range index branching off those branches.
When it comes to YugabyteDB splitting data into tablets, each fork - that is, value in a column, is an opportunity to split the data into a new tablet.
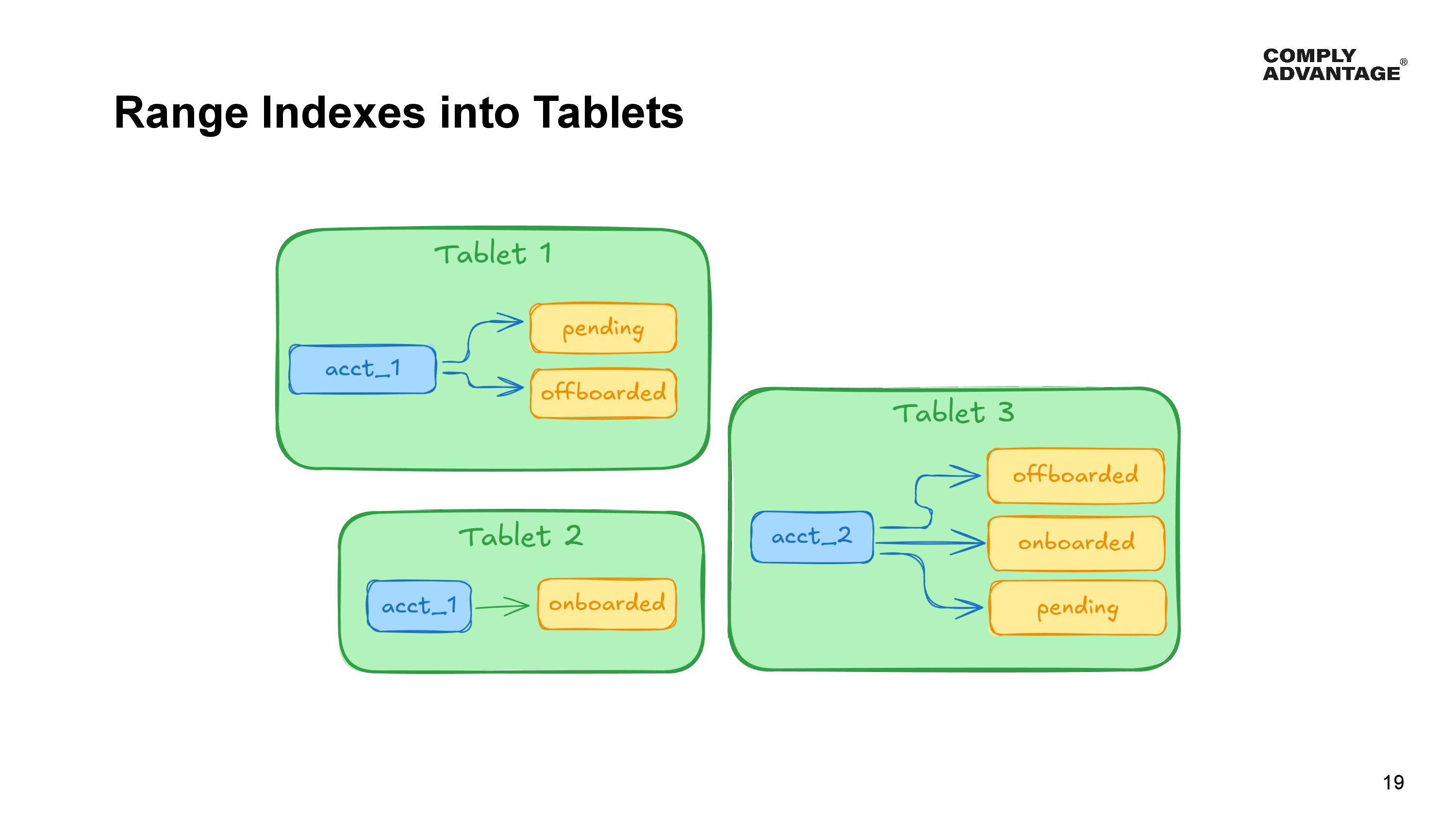
Because a range index can be split at any fork in the tree, different parts of each tree can be in different tablets.
In our example, both the account and state columns were sorted in ascending order. So YugabyteDB could:
- Put pending and offboarded customers for account number 1 into Tablet 1.
- Put onboarded customers for our big account number 1 into Tablet 2.
- And put all the customers for account number 2 into Tablet 3.
But most importantly, it cannot split any individual value into two tablets; it can only split at the forks. This means it cannot move half the onboarded customers for account number 1 into a different tablet - they must all reside together in the same tablet.
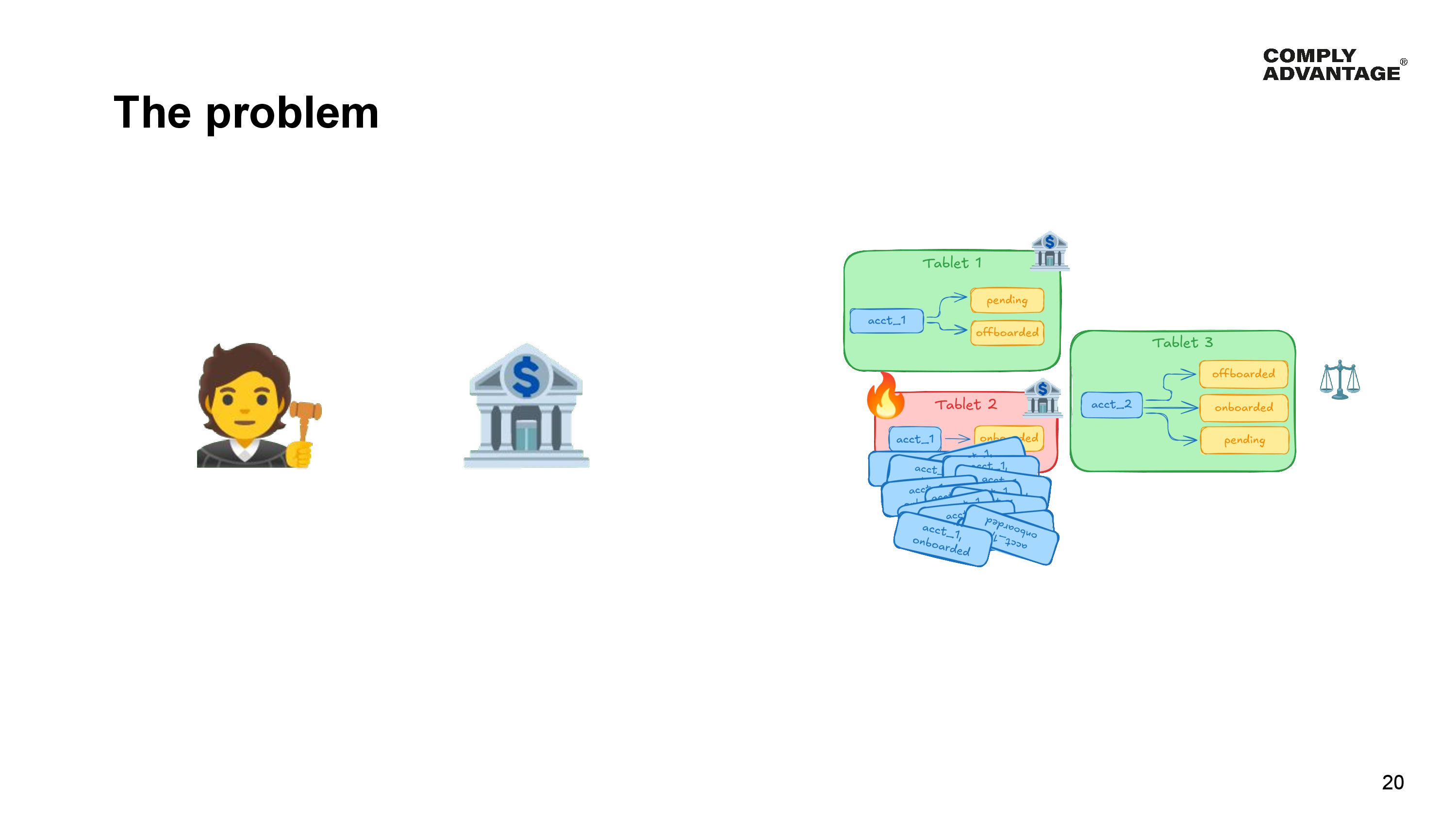
Remember our problem from earlier is that not all of our clients are the same, and if a large client is successful, most of their customers will be in the onboarded state. This leads us back to poor data distribution amongst the cluster, with this particular range index tablet containing all customers for account 1 in the onboarded state.
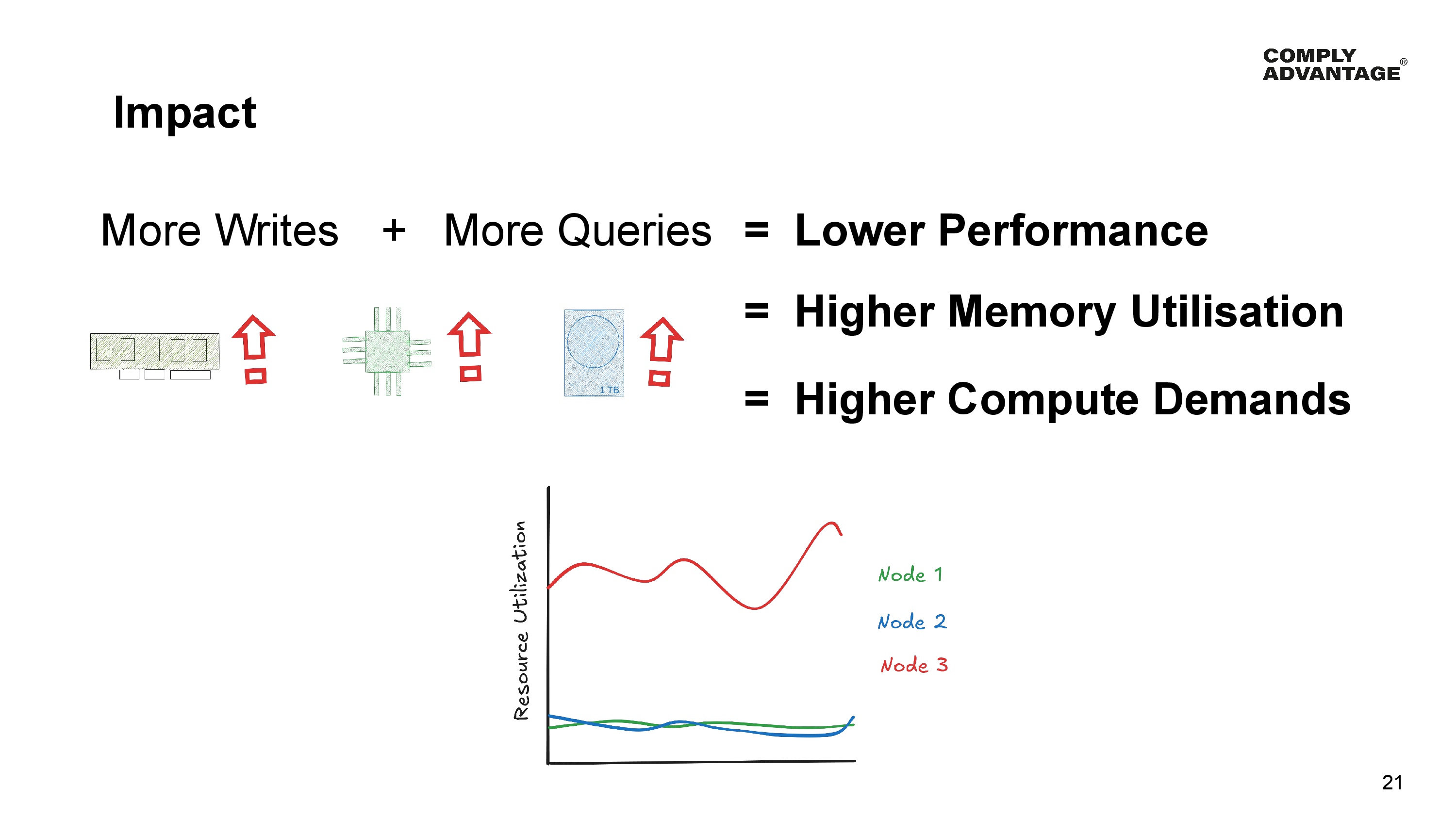
This leads us to the same impact as in the previous scenario.
More writes and more queries going to the same tablet result in:
- Lower performance
- Higher memory utilization
- Higher computing demands on the node hosting the Tablet.
- And the same costs when it comes to vertically scaling the entire cluster to handle the largest tablet.
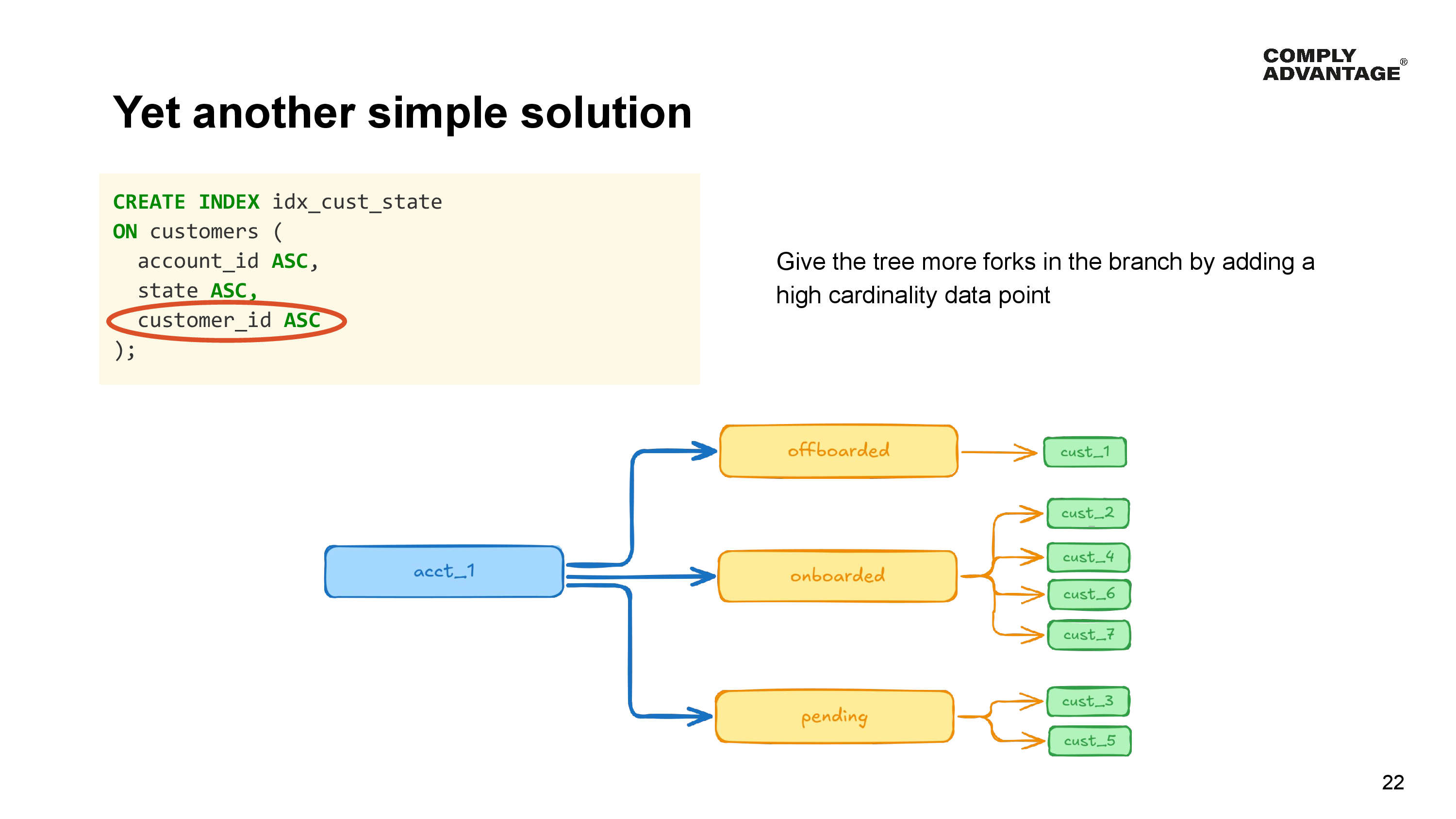
To enable a better data distribution, we simply need to give the tree more forks.
Since at query time, we don’t need to specify all columns in a range index as part of a where clause in order for the query planner to use it, we do this by adding an extra column with high cardinality to the index, thereby providing a lot more forks in the tree for YugabyteDB to split the data.
In our example here, we’ve added the customer identifier to the index. Given each record has a unique customer identifier, there is enough cardinality to provide many forks.
We could also have used a created or updated timestamp. Since it doesn’t matter what this data point is, just that it has a high cardinality, we could even add a synthetic discriminator column to the table if you have nothing that is already suitable.
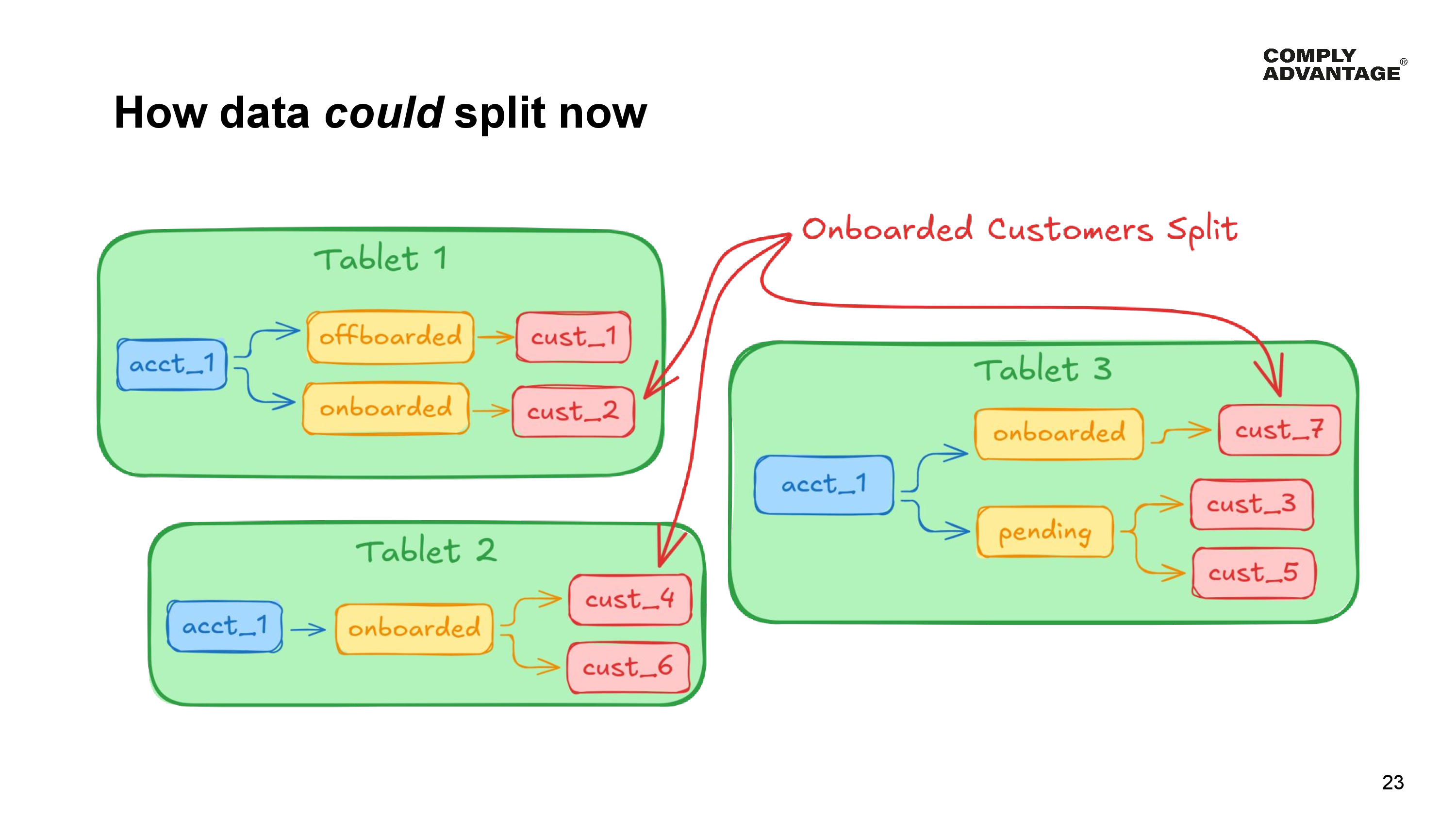
By making this simple change, YugabyteDB now has the freedom to distribute the data much more evenly than it did before.
- Onboarded customers can be split into individual tablets, instead of needing to be grouped into the same tablet.
- Some onboarded customers, number 2 for example, can be stored in Tablet 1.
- Onboarded customers 4 and 6 could be stored in Tablet 2.
- And onboarded customer 7 could be stored in tablet 3.
Of course, this comes with a few costs we need to consider:
- The first is a larger index on disk since more data needs to be stored.
- Queries for all “onboarded” customers possibly needing to hit more than one tablet.
But these are trade-offs you sometimes need to make in order to ensure your data is evenly distributed - sacrificing slightly larger indexes, hence storage cost, with balanced clusters, and typically, the additional cost of the slightly larger indexes is significantly less than having to scale the cluster vertically to account for a single giant tablet.

There are a few lessons we have taken from making mistakes similar to the ones described so far.
Some of these mistakes were made because engineers just didn’t know what the defaults were in any particular scenario.
For example, if you don’t explicitly specify anything, the first column in a primary key or an index is always treated as a hash.
So the first thing we learnt here was to always be explicit about the role a column plays in any primary key or index by requiring our engineers to explicitly define hash, ascending or descending for each column in their indexes.
This not only makes the intent clear to whoever is reviewing database migrations but also to whoever runs across the migrations in the future.
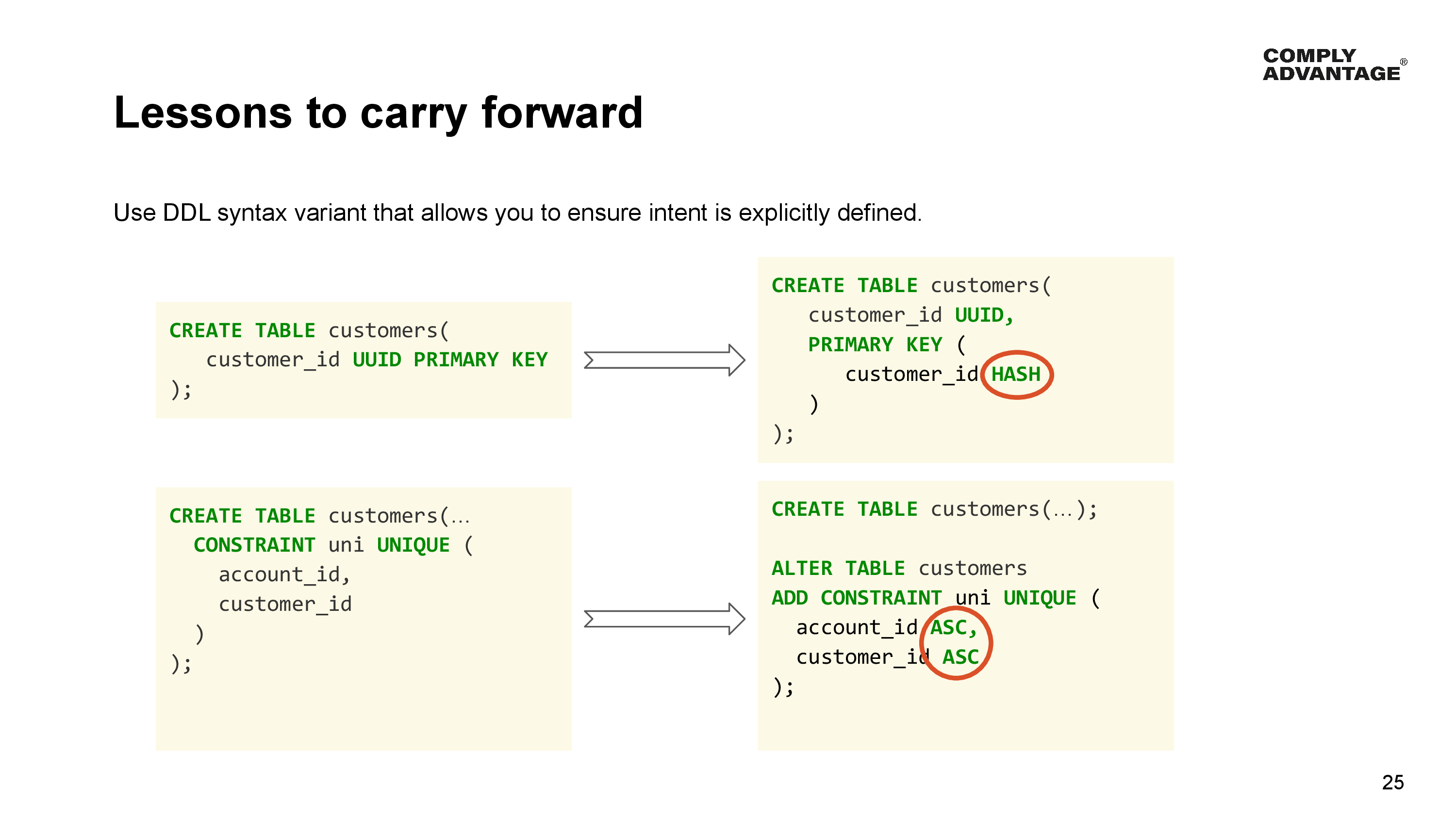
In some cases, YugabyteDB doesn’t even allow you to specify the role of a column. So we ask engineers always to use a DDL statement that lets them explicitly define the roles of each column so the intent is explicit and clear. For example, when using column syntax for defining primary keys, the column marked will always be a hash. We avoid this in favour of a primary key definition that allows this to be explicit.
Another example is using inline constraint definitions. YugabyteDB does not allow you to define the roles of individual columns when specifying a composite constraint. The first column is always a hash, and subsequent columns ascending order with no way to override.
There are alternate approaches that work, such as creating constraints using an altered table statement, which allows you to define the role of each column.

We also ask engineers to ensure that by default, their primary keys are just about identity. Don’t try to force them to perform more than one function - for example both identity and satisfying one or more query patterns. You can create indexes to satisfy those query patterns instead.
Finally, it’s important that engineers understand the consequences of bad data distribution, so they can identify it when developing schemas. We do this by publishing data modeling guidelines that engineers can reference when implementing their statements.

So we learnt that not understanding how data is distributed amongst tablets in YugabyteDB can cause problems, and the key takeaway from this lesson is to always understand both the purpose and cardinality of each column in a key or index and not rely on defaults - be explicit.
A bit of planning up front can avoid a lot of pain later, especially since it is so expensive to re-key tables if you get the primary key wrong.

OK, it’s time for lesson 2 - which covers the necessity of tailoring statements for Distributed SQL, and we’re going to use YugabyteDB Upserts as a case study.
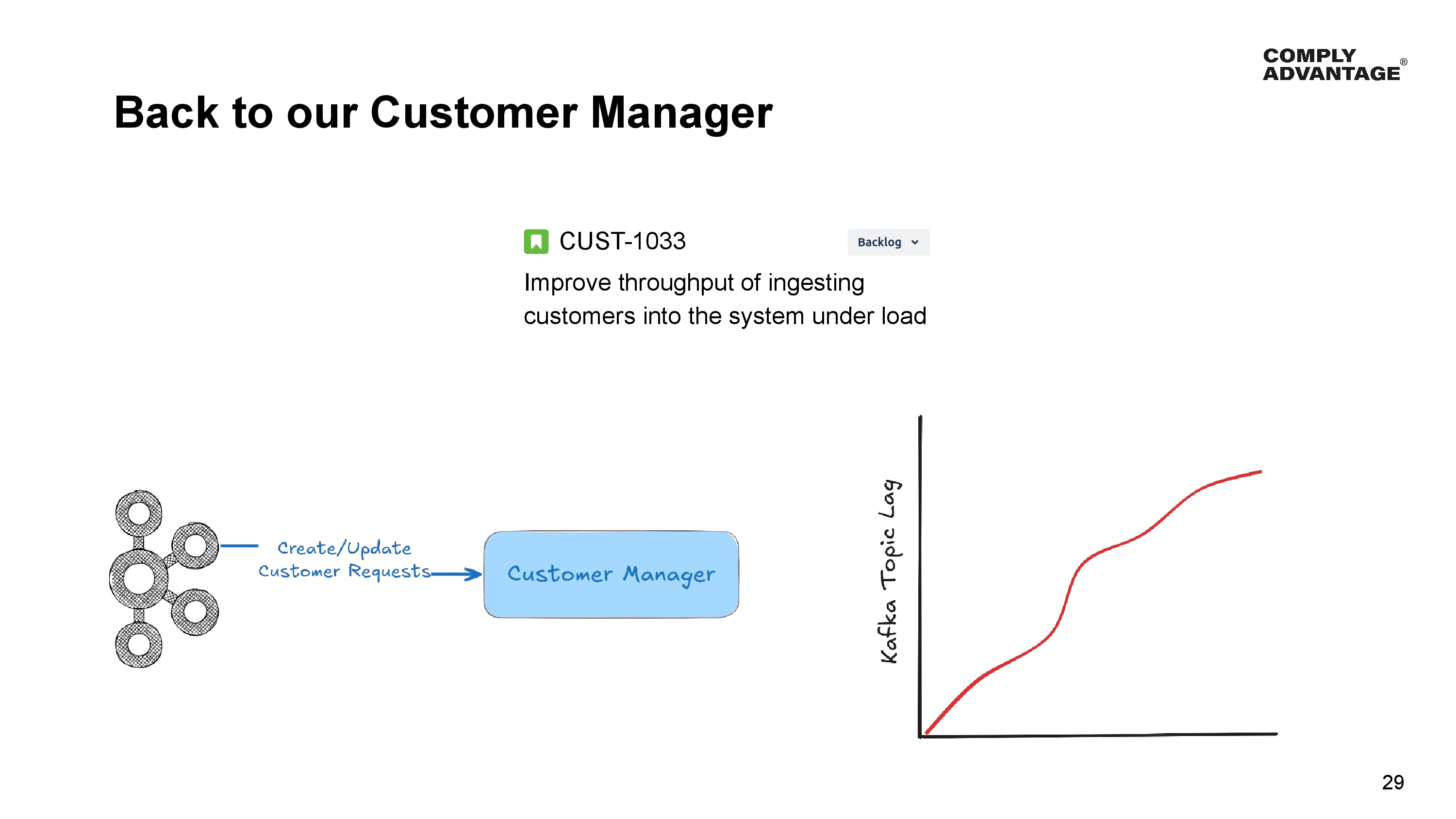
Let’s revisit the customer manager. Our Product Manager has asked us to improve the throughput while ingesting the customers under load.
If you remember those large customers from our previous lesson, sometimes they might drop a spreadsheet containing hundreds of thousands of customers. This most commonly occurs when they upload back-books of customers shortly after they onboard onto our platform. We want to create a good impression since our relationship with them is new.
In order to do this, we try to ensure we process their customers in a timely manner, allowing their analysts to access the results as soon as possible.
Now the customer manager processes these requests as they arrive from Kafka, but it currently processes one message at a time, and it can’t process fast enough when these large spreadsheets arrive - its topic lag increases, and it takes a long time to process all the new customers.
This creates a bottleneck for other parts of the system - the ones that do sanction screening and risk analysis.
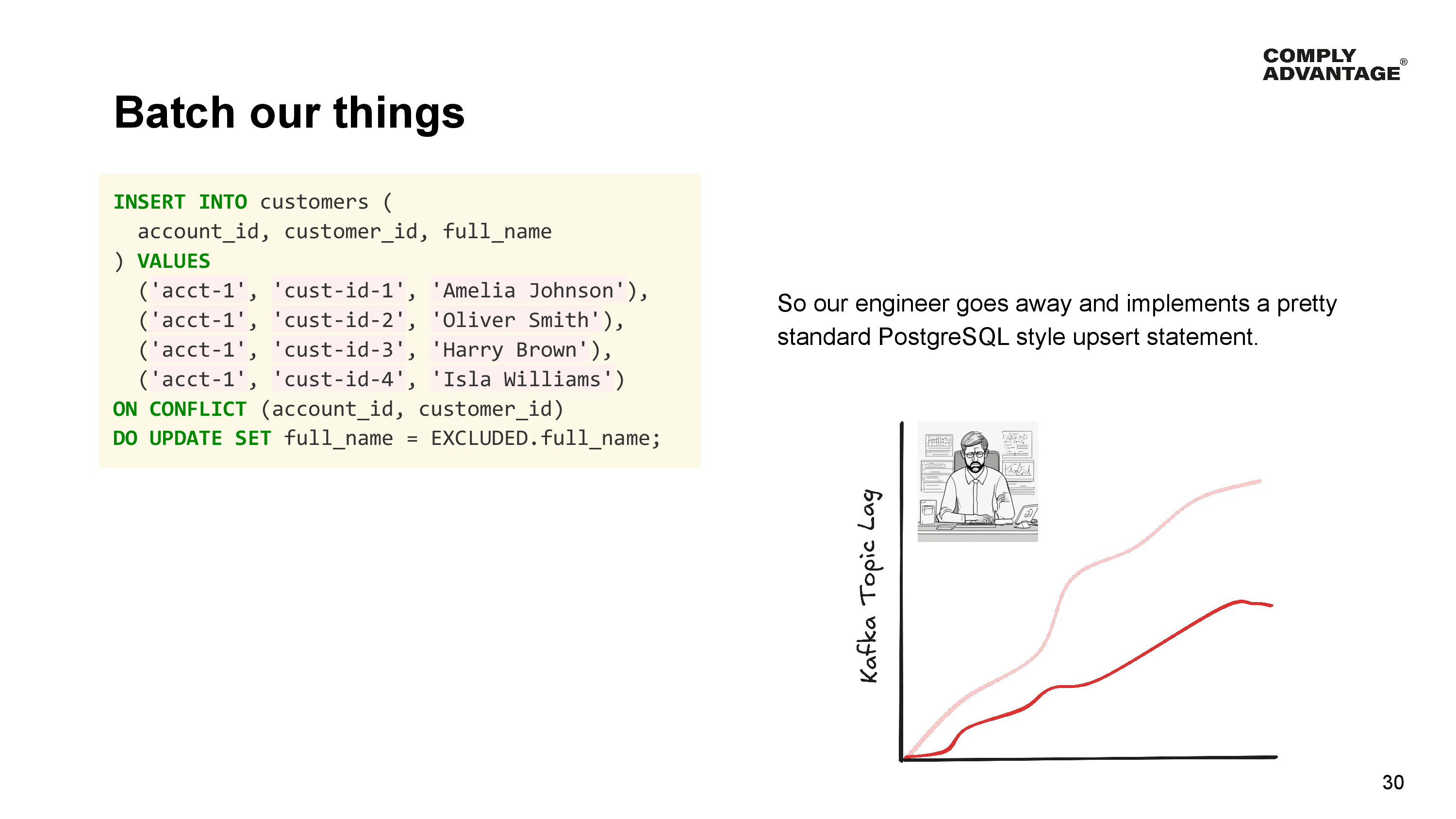
So our engineer goes away and implements a pretty standard PostgreSQL style upsert statement.
Upsert statement:
INSERT INTO customers (
account_id, customer_id, full_name
) VALUES
('acct-1', 'cust-id-1', 'Amelia Johnson'),
('acct-1', 'cust-id-2', 'Oliver Smith'),
('acct-1', 'cust-id-3', 'Harry Brown'),
('acct-1', 'cust-id-4', 'Isla Williams')
ON CONFLICT (account_id, customer_id)
DO UPDATE SET full_name = EXCLUDED.full_name;
A picture of the Kafka topic lag decreasing, but still not good enough/flat.
So we changed our Kafka consumers to process messages in batch, 500 messages at a time, and since we’ve done this our engineer altered our repository implementation to batch the upsert operations.
When we performance-test this change we find that it doesn’t make as much of a difference as we hoped. Sure - it’s a little better than it was before since we have optimized other parts of our service for batch as well, but we are not seeing the gains we were hoping for, and our Product Manager wants more.
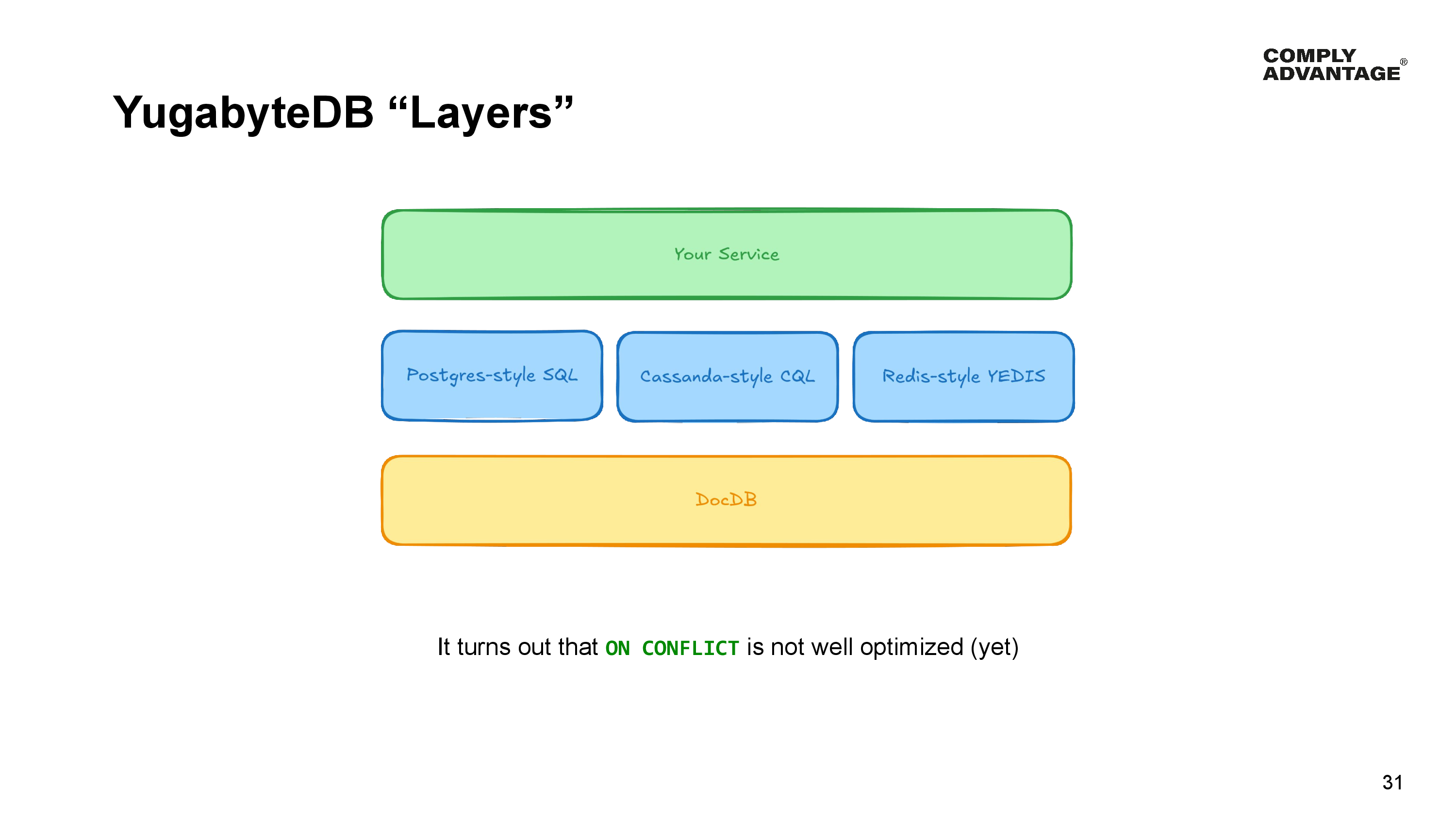
Now we’re digging a bit into the way YugabyteDB works internally here, but this is important to understand why we didn’t get the performance gain we were expecting.
The data in YugabyteDB is actually stored in DocDB - the underlying storage layer and YugabyteDB provides different layers on top of DocDB for query and DML statements:
Each of these layers sends requests down into the DocDB layer to perform data manipulation and queries. It turns out that “ON CONFLICT” isn’t particularly well optimized yet.
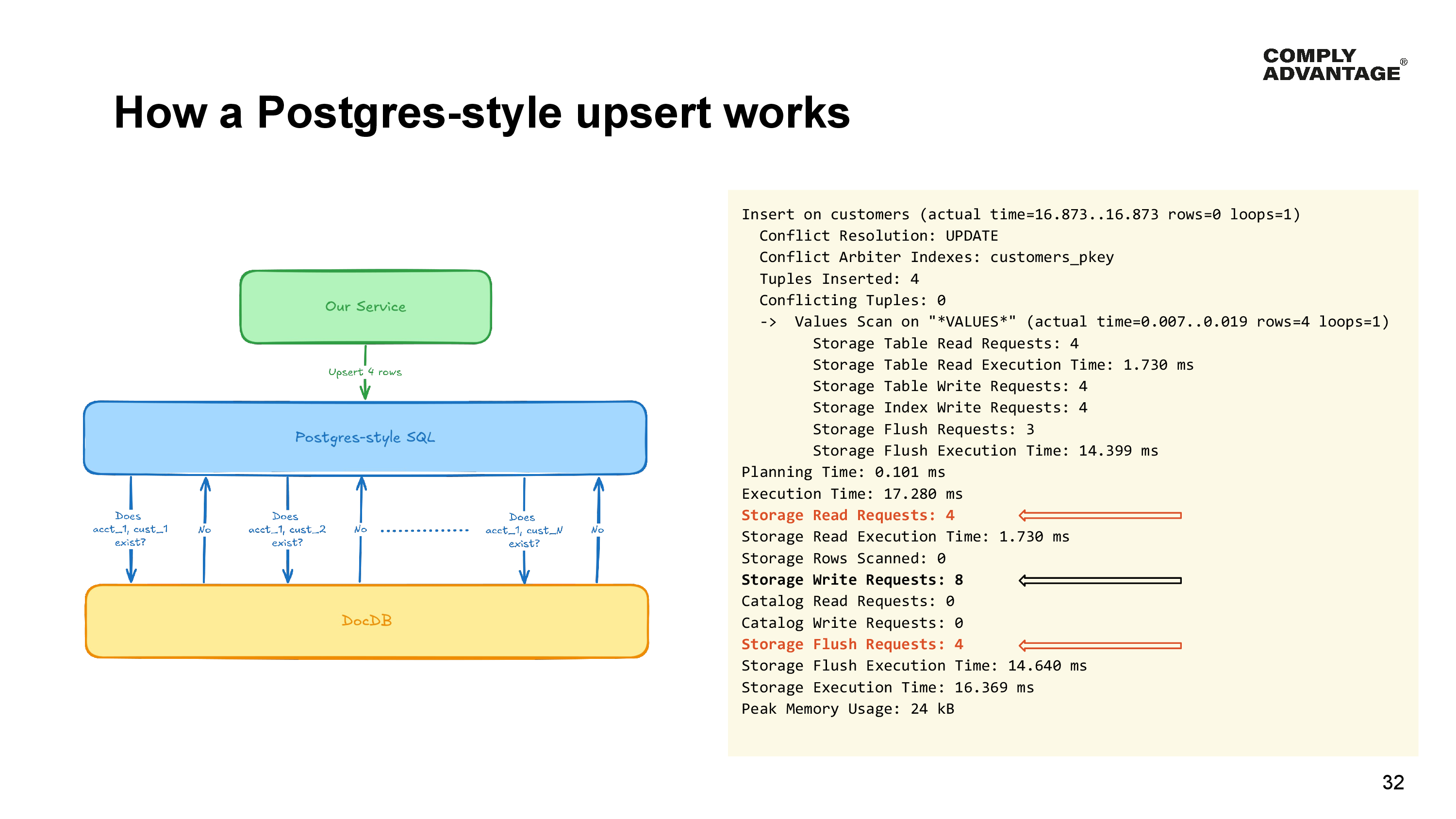
What happens when we use our Postgres style upsert, is that for each row we want to upsert in order to determine the correct thing to do, the Postgres layer needs to talk to the DocDB layer to find out if there is a conflict.
We can see the cost of this by looking at a query plan created by running EXPLAIN ANALYZE with the DIST option enabled. A few interesting things arise from this query plan. The Postgres layer has made :
- 4 individual Read requests down into DocDB
- 8 Write requests (we’ve had to write one row to both the table and our state-based index)
- 4 Flush requests.
So this isn’t the right approach to solving our batch upserts, but there is a way to make this a lot faster.

We can leverage Common Table Expressions to do the work of an upsert. This significantly improves the performance of our upsert operations. Let’s see how it works.
First, we need to enable Batch Nested Loop by setting a variable - yb_bnl_batch_size. What value to set here really depends on your scenario. Thankfully, in this case, we can get away with setting it to 4 because we have 4 values to upsert. Beware of setting this value too high though, since a higher value will allocate more memory to the statement we are about to build even if you only have a few rows. Enabling the batch nested loop allows the YugabyteDB to generate more efficient query plans as it can transport multiple rows around together between the DocDB and query layer instead of iterating row by row.
Next, we create the values named expression containing all the rows we want to upsert. So far this looks pretty simple.
Then, we create a named expression updated which updates any rows from the values that already exist in the database. This named expression, once executed, will contain one row for each customer that was updated. In our values here, if Harry Brown’s row was already in the database, his full name would be updated.
Finally, we create a named expression to insert any rows from values that don’t exist in the updated named expression. For example, Harry Brown would not be inserted since his update would be inside the updated result set.
When we look at the query plan for this method, we can see the overall execution time has dropped from 17 to 7 milliseconds. This drop is more pronounced with a larger number of rows.
This improvement is largely due to the number of read requests having dropped from 4 to 1 (or in the case of a batch of 500 records, it could drop from 500 to 1 since all operations can be done in a single call from the Postgres to DocDB layers), whilst the number of storage flush requests has dropped by the same amount.
Of course, the number of writes remains unchanged since ultimately we are performing the same number of writes in the table and index.

Depending on your scenario, you may need to vary your implementation. I am not going to go into great detail here, but if your upsert batches are going to be updating a lot of columns, it may actually be faster to delete any current matching rows and then insert all the values supplied to the statement.
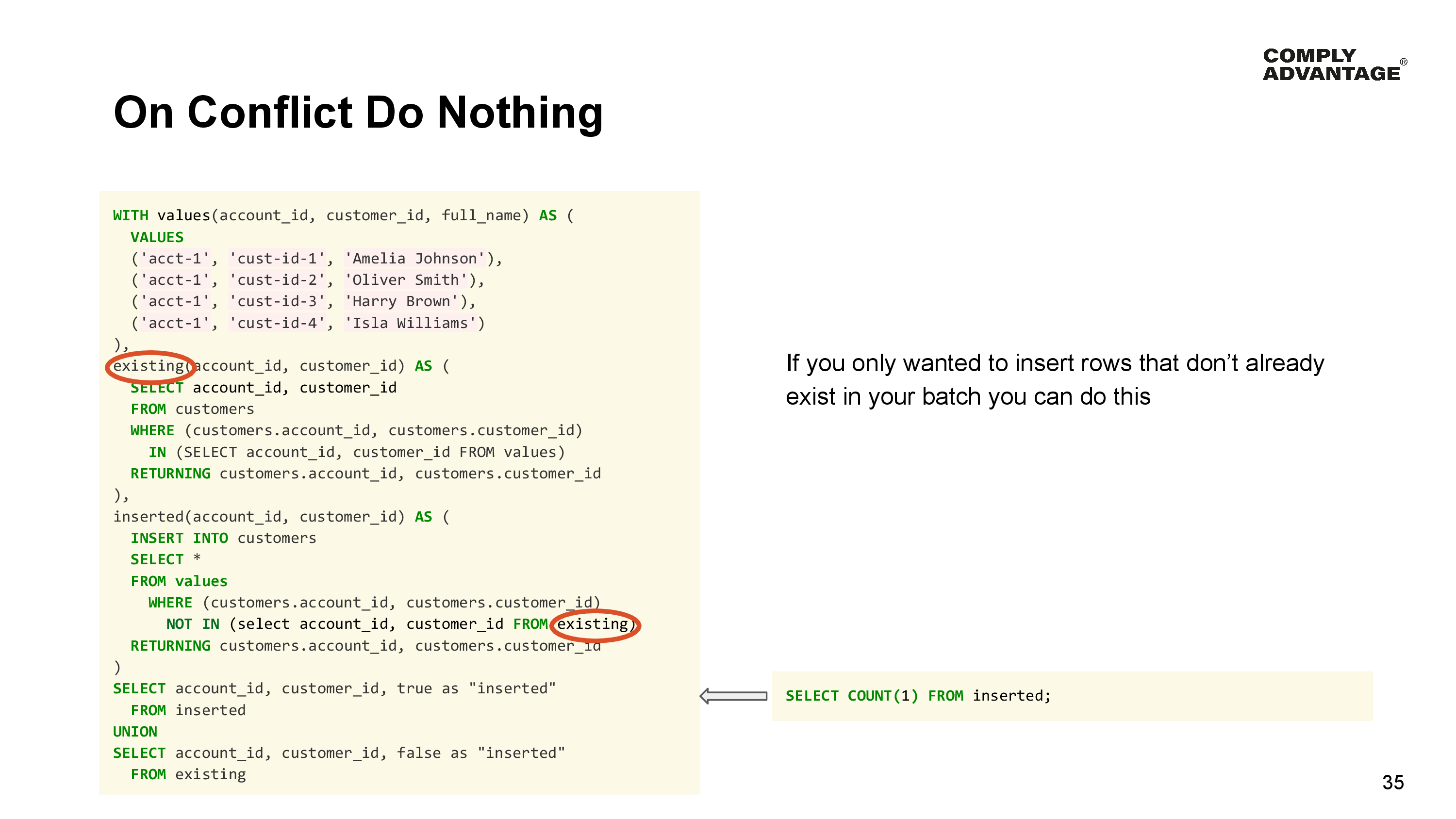
If you only wanted to insert rows that don’t already exist in your batch, you can do this.
On Conflict do nothing has the same performance characteristics and can also be optimized similarly by using a named expression to find any existing rows - this is the existing named expression in this statement. We can then use the results of this query to only insert rows for ones that don’t exist in the existing named expression and return the identifiers and classify them by which ones were inserted and which ones were skipped.
Of course, this final statement could be anything, including just a count of the rows that were inserted.

But be careful when your values to insert contain duplicates such as our example here. Unlike conflict statements, which will always result in the last value taking precedence and being inserted, doing it with a Common Table Expression will cause a unique constraint violation. Therefore, it is important to de-duplicate values in client code instead. This can happen, for example, if your source batch contains an insert and update for the same customer.
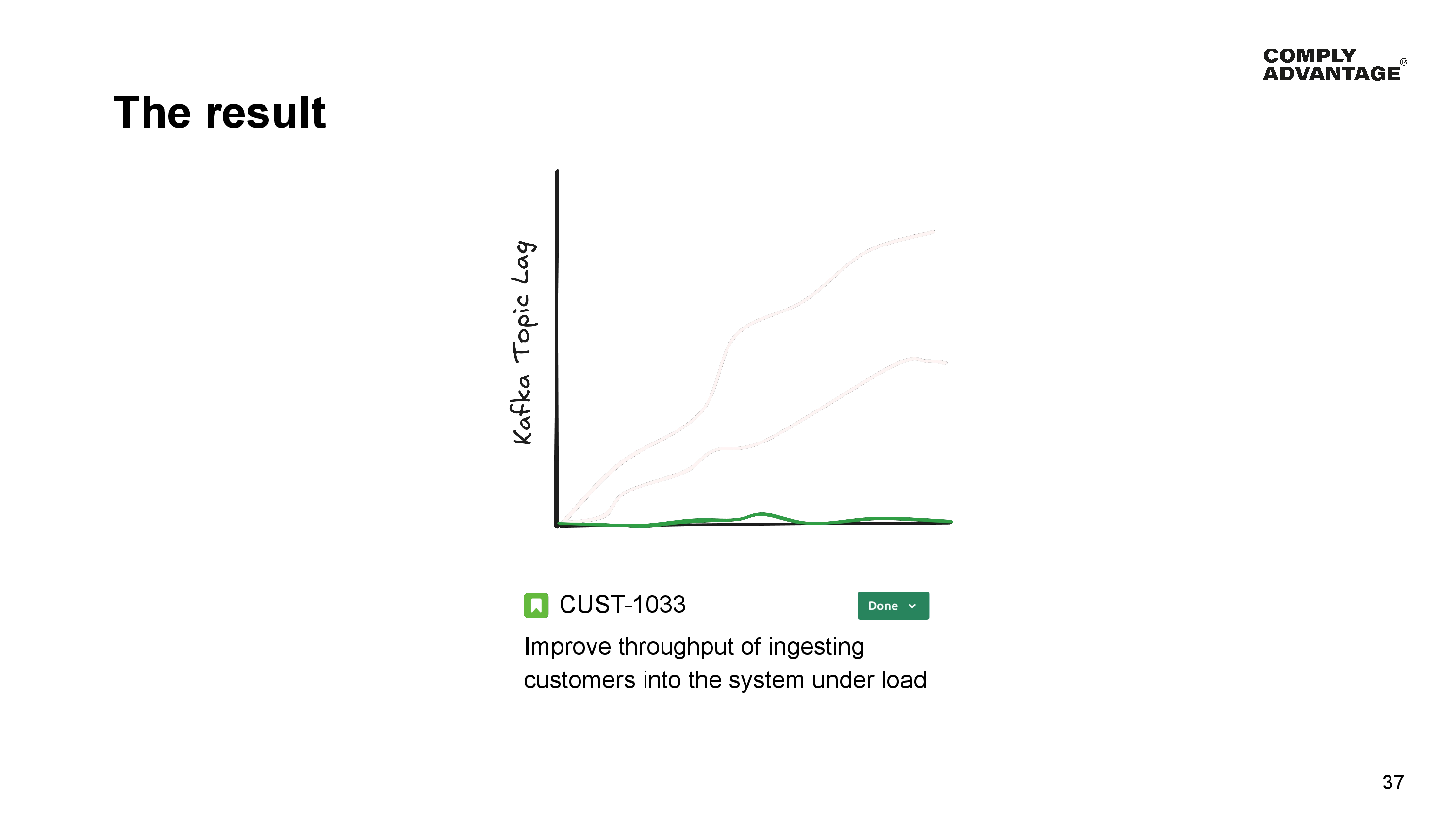
After all this work, we show the product manager the results. The Customer Manager is no longer the bottleneck and is able to keep up with its input load, and the ticket is moved to done.
And once again, there are a few lessons we have taken from making mistakes similar to these. The first is that although YugabyteDB is largely compatible with the PostgreSQL dialect, it is not Postgres. Some features are missing, but importantly, the performance characteristics of approaches to solving problems can be vastly different, so performance testing is critical on anything that seems like it could be performance-sensitive.
Secondly, when you find these differences, create recipes and documentation for your engineers to follow, so there are recommended approaches to solving these issues. This will help save a lot of engineering time by avoiding the problem in the first place, as well as ensuring you discover and invent solutions only once.

If there’s only one thing you take away from this session today, it’s that understanding the characteristics of your chosen Distributed SQL database is important for the long-term health of your services and data infrastructure. That understanding must be spread across all the engineers in your organization, not just siloed to a few subject-matter experts. This understanding is very much the root of the vast majority of the lessons we have learnt in the last 18 months - not just the 2 I have spoken about today.